Alternative data has become an important, and perhaps indispensable addition to most quantitative strategies. We had the pleasure of talking to Rado Lipuš, the founder and CEO of Neudata – one of the industry’s leading alternative data scouting platform. Rado has over two decades of experience in the industry, ranging from FinTech and data innovation for the buy-side, to quantitative portfolio construction and risk management. His breadth of experience, coupled with the knowledge of how end-users treat alternative data, makes him uniquely positioned to understand the needs and trends in the industry. Rado received his Master of Business Administration from the University of Graz in Austria and is a CFA charter holder.

CFM: A soft ball to start… For those who might be unaware, how would you define ‘alternative data’?
RL: Five years ago, when I started Neudata, it was much easier to define – it would typically refer to very niche data sources that were not available on major platforms, or were just emerging because of new technologies. Think for instance satellite, web-scraped, or mobility data – nearly anything that is beyond typical price or company filings.
Today, with so much more data, we are steering away from this term ‘alternative data’, simply because what would have been deemed ‘alternative’ five years ago – say, for example, sentiment data – is now being used by nearly all quant funds. If its use, as is clearly the trend, becomes ever more ubiquitous, we have to ask whether it is still accurate to call anything used by most market participants, ‘alternative’?
I don’t think so. And I believe it doesn’t really matter anymore; it is all just data. It is our mission to capture any sort of data that could be useful for our clients, most of whom now routinely use data that used to be deemed ‘alternative’.
CFM: Do you have any classification or tracking structure for the different data sources on your platform?
RL: Yes. However, it is important to bear in mind that there are many nuances. It is not uncommon for a specific data product to leverage multiple sources, and be relevant for multiple use cases.
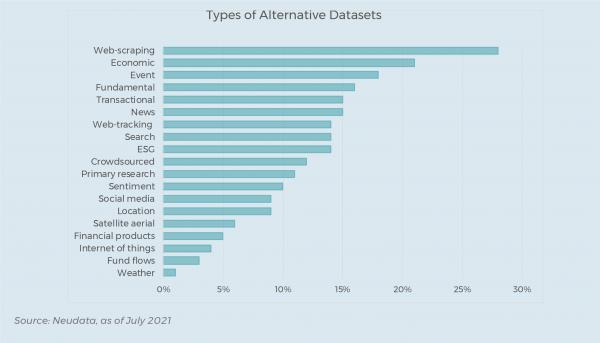
Nevertheless, today we maintain ~5,700 unique data sources on our platform, which we group into 19 major categories. The biggest category is web-scraping, which is no surprise – the barrier to entry for web-scraping is very low, and there is so much valuable information to gain from these sources.
I will add that something that classification difficult, if not misleading, is that many of the most advanced providers will complement their source with various additive overlays, such as location-based inputs, which adds a granularity that makes the data much richer and easier to work with.
These types of overlays have many benefits, including making the end-user market much larger. Being able to work with ‘cleaner’, more comprehensive datasets allows more funds – particularly those that can’t afford a small army of data scientists to work on the data – to join the race.
CFM: When was Neudata launched, and why did you see the need for a firm like yours?
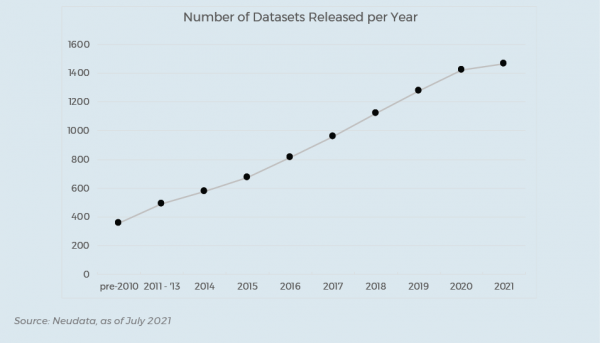
RL: Apart from personal ambitions, there was a clear business case. Having worked extensively with quant funds throughout my career, I observed first-hand the strategic and central importance of data, and often the difficulty of finding valuable data sources. Around 2015 the first data scouting jobs emerged, when many funds realised that there was value in centralising this function. So the value proposition, at first, was finding and listing data sources which was initially quite hard, for there weren’t that many data sources (nor good data sources).
The value proposition has since changed completely. Today it is quite easy to find plenty of sources, so the challenge has become to find the right vendor, that offers quality data, which can be deployed for the right use case. So in short, as the amount of data sources (and potential use cases) exploded, the challenge has become vetting, understanding the compliance risks, and assessing whether the data is any good, whether it is useful, and also, whether it is priced appropriately.
The vast universe of data can make it quite challenging and cumbersome to identify the most useful and appropriate data. So we have expanded our offering from purely data sourcing, to becoming a more holistic advisory firm for our clients.
CFM: A key value proposition that stands out for me is the pre-vetting of data sources, reducing some of the initial heavy lifting. What is your process in separating the wheat from the chaff?
RL: Indeed. This is in many ways the crux of what we do, independently vetting all data sources before they make it onto our platform. We have developed an approach where we first perform due diligence on the vendor, and then analyse the data objectively. We analyse data on 100+ factors (varying depending on the type of data) which screen for particular attributes – not only on the metadata, but also on any potential compliance issues, data protection issues (that vary across jurisdictions), legal risks, permanency risks, etc.
For any fund, ingesting, cleaning, trialling, testing and backtesting data comes with substantial cost – not only because the trial is perhaps charged, but more importantly because of the time it takes. Your return on all this effort can be very low if there are unforeseen issues with the data, which is something we can mitigate.
What we are effectively trying to do is to increase the hit ratios of even very skilled funds.
CFM: Do most funds, even for the most sophisticated ones with armies of data scientists, take advantage of the centralised and vetted benefits of a firm like Neudata?
RL: Five or so years ago you wouldn’t have had a choice. You would have to have done the scouting, vetting, etc. all in-house. Today we have substantial intellectual capital invested in the platform, so that funds that use Neudata end up with costs that are much lower than hiring a senior data scout (who might not even have access to all the resources and communal knowledge that a platform like ours possess). It becomes valuable, even for the largest funds, since we have economies of scale. We are able to syndicate the research and provide information in a very cost effective and timely way.
Another important attribute is that we have unique insight into pricing and the demand-supply dynamics: What are the trends? What are our clients thinking about any given data source? What is useful or not? How are the offerings are changing? There is a collective intelligence that’s derived from having conversations with both data buyers and sellers.
Our client base is comprised of funds of all sizes and across all different types of strategies. Even the biggest funds – which may have a dozen data scouts – still leverage our service, because one, it saves them time, and two, we provide industry insight and can offer a bespoke service if, say, a fund is looking for a very specific, niche dataset.
CFM: Who, today, is your typical client, and has this evolved away from mostly quantitative focussed funds and clients?
RL: It has changed significantly. When we launched, and even for a period thereafter, our core clients were mostly quant and systematic funds. Then, from about 2018 onwards, a significant wave of interest from ‘quantamental’ managers, but also from the likes of private equity emerged.
More recently, following the Covid crisis, we are seeing increased interest from corporate clients as they become aware of the vast amount of ways they could use location-based data (for logistics companies) and especially transactional data (for consumer companies). We are working with these firms on how to either use data themselves, or advising them on how they could monetise their in-house sources of data for the market.
CFM: Has the typical requirements / format of data, and the typical use cases also evolved?
RL: Indeed. Five or so years ago quants would typically require, for example, a dataset with at least 10 years of history, covering 2,000+ of the most liquid stocks, and ideally would have been tickerised. However, today, most of the top funds have already looked at most of those datasets. Funds are moving in a new direction and are now eager to look at very specialised data sets that don’t necessarily have a long history. They could even be very narrow and sector specific. The criteria is much less stringent and the application of that information might be different than it was five years ago.
Some of our early clients realised there could be very valuable information in these datasets, perhaps for launching funds with a very narrow remit – which, of course, can be very lucrative as it is a much less crowded space.
Many clients recognise that the more focussed, often overlooked datasets (on account of most going for the most comprehensive datasets first), can prove very profitable. It is ultimately hard to find alpha, and the smarter funds are willing to do the extra legwork.
There is also much more interest in niche datasets, and datasets beyond developed markets – China, for example, is a region where there is fast growing demand. It just requires a bit more creativity to monetise this type of data but it has proved very lucrative for those making the effort.
CFM: You mentioned China – do you still see a substantial discrepancy between developed and emerging markets in the availability of alternative data?
RL: Yes, but this is quickly changing, with a big trend being both the supply and interest for non-US data. And equally, demand is increasing for data from the entire Asia-Pacific region, as well as from Latin America. Many of the most sophisticated quant funds are already using much of the data from the US. Some are transferring their research and know-how, primed in the US and other developed markets, to China and other emerging nations as the quantity and quality of alternative data there increases. Being more nascent, and being fraught with regulatory traps, there is still more alpha generating opportunities in those markets.
CFM: Typically, alternative data had the most obvious application in public equity markets. Have you observed any notable shifts in the application beyond mostly equities?
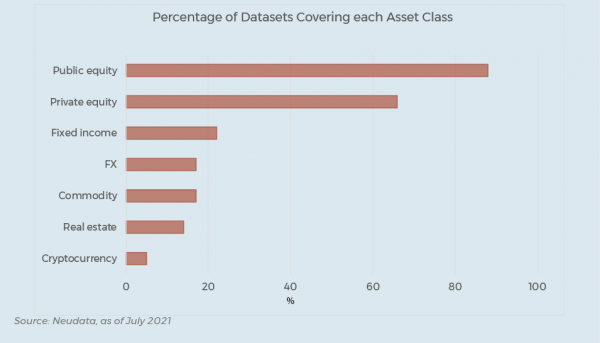
RL: It has definitely changed, with both a much broader demand and supply of data beyond equities. Nevertheless, equity remain the dominant asset class, with 88% of the datasets on our platform focussed on equities. However, we have seen a significant amount of growth in the number of available data applicable to the fixed-income space, for example, with just over a fifth of datasets on our platform applicable to this asset class.
CFM: It is clear that the rise of alternative data and the way it is being employed has had a substantial impact on the industry. How have you seen quantitative managers adapt in order to exploit this trend?
RL: We see a broad spectrum of adoption approaches. It ranges from those that have achieved scale and have industrialised the whole process, to those who are probably playing a bit of catch-up, who are still only looking at staple-type data sources, many of which have already been widely adopted.
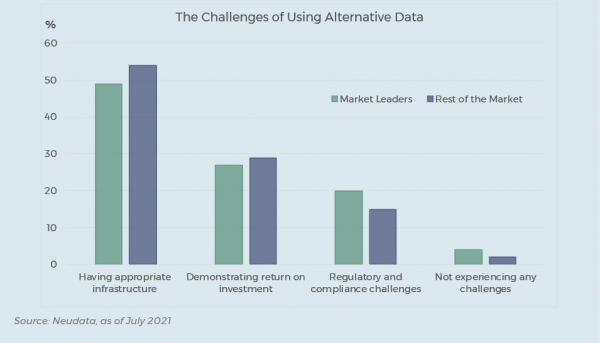
Some of those funds are still ramping up their processes so that they can increase their research capacity from testing, say, five to at least twenty data sets per month. But beyond the research work, additional structures are required, and in those areas, we see funds with a wide range of levels of preparedness. While research is key, successful data usage also requires funds to have a smooth procurement process, a good due diligence and compliance structure, and to be cognisant of and have processes in place to mitigate all the inherent risks.
However, with the continued rise in the number of alternative data sources, the aim for most serious managers is to put repeatable structures in place to industrialise the process, so as to increase their ‘hit rate’. A good proxy is typically the conversion rate, i.e. a rate of 20% of data in production from all the data that have been tested is quite high – meaning you are quite early in the stage to industrialisation. Whereas if your conversion rate is 10%, it should mean you have probably tested hundreds, if not thousands of datasets.
CFM: You’ve now frequently mentioned compliance considerations. How much care is needed to understand the legal and or compliance considerations for some of these data source? Web-scraping comes to mind as one source that has enjoyed much legal scrutiny…?
RL: There are, for most web-scraping sources, few legal entanglements. Of course, there have been a few well-covered legal cases and we monitor developments in this space very closely. In a way, these few cases, while important, overshadow the reality a bit – the majority of data sources can be used with little risk and high confidence.
Might I add, on this topic, there are a few more serious risks to consider with web-scraped data in general.
One problem, even more poignant than legal risks, is discontinuation risk. We expect a high percentage web-scraped datasets to come off the market every year. Managers should be cognisant of this risk as it could be quite costly to manage and mitigate.
Another is simply quality. There are hundreds of these data vendors, and we are especially careful when assessing web-scraped data sets, because many are just noise with very little added value.
CFM: To pause on some of the risks associated with potentially the slapdash application of alternative data. Following the Covid crisis, alternative data moved very quickly into vogue (I can think of e.g. mobility data to track economic activity). What do you see as some of the pitfalls in the reliance (or perhaps over reliance) on this type of data?
RL: You’re right. The risks are high, especially given that the supply side is so vast. To identify the right dataset for the right strategy or use case is paramount. We have often seen managers attending conferences, meeting with vendors with slick sales teams, and acquiring data without the necessary due diligence or considering how the market already feels about a vendor. There is a risk that, while data may be inherently valuable, it might not be appropriate for your needs.
Cutting corners by not doing, for example, a thorough comparison between data vendors can be both costly and a wasted effort.
The other dynamic which is often overlooked is the power of combining datasets. There is nearly always a dataset that can be very additive to another dataset, and it can be very rewarding to understand the interplay, nuance and overlap between datasets – something many overlook and that we help advise on.
One also has to remain vigilant about changing dynamics and the underlying factors that make any one dataset valuable – because these can and do change.
CFM: On changing dynamics and trends: You recently released your H1 2021 ‘Alternative Data Trends’ report. What would you highlight in this report, and what, if anything, surprised you?[1]
RL: Interest in ESG. It typically ranks in the top three, if not the top two of client enquiries. And it is not just rating-agency offerings, but data that might not be labelled as ESG-applicable, but can be used for that purpose. However, we still notice many issues with this type of data – availability and frequency are typically the biggest concerns.
Another clear trend to highlight is the interest in non-US transactional data sets – whether it be credit, debit or receipt datasets. The world has caught up with US transactional data, with dataset availability growing in European markets in particular, as well as in some countries within the Asia-Pacific region and Latin America.
Now, you might not necessarily be able to trade many of these markets because they lack liquidity, but we expect many more of these datasets to become available and the interest in them to grow. Especially on the invoicing side – we have more and more listed companies that are considering monetising their data and we are advising them on how best to make this type of data available. When this type of data comes to market, it should stir a lot of interest.
CFM: On ESG – much more quantitative data is becoming available, which requires more data insight and know-how to assess companies on a wide-range of metrics. This is a strong departure from the initial, historical way of investing in ESG, which was mostly screening and ethically driven, or reliant on aggregated scores from vendors. In many ways, in order to actively manage an ESG portfolio, becoming more data reliant, rather than less, is probably what is going to be needed. Does this rhyme with what you are seeing from clients?
RL: Definitely. The difficulty of ESG is also the opportunity. Many of our quantitatively-minded, but also more fundamental, bottom-up clients recognise that in order to gain an informational edge, more data – and more niche data – is going to be needed. They already recognise some of the benefits and use cases of leveraging aggregated, credit-risk-like rating agency scores of firms, but certainly not necessarily for alpha generation.
We are seeing the same trend on the corporate side – they too face the same problem with data scarcity and quality. If you are a large company with complicated supply chains, you too want to know the profile of your suppliers and partners, and how they measure up against contemporary standards and regulations.
It is simply a very complicated and multi-dimensional problem, with no satisfactory off-the-shelf solution. So, for many of our more sophisticated clients, the reality is that the research and data analysis has to be brought in house. This trend, however, is in very early stages and will undoubtedly mature much further. And while Europe has led the charge, the US is catching up. I will not be surprised if this acceptance in the US has a dramatic effect on the uptake of ESG on a broader scale.
We are making every effort to remain up to date on these developments, and we are hiring two more analysts on our specialists ESG research to tackle all of our client questions surrounding ESG.
CFM: Your expectations and forecast for the alternative data industry? Any niche areas that you are keeping an eye on?
RL: First of all, alternative data has become table stakes – you cannot ignore it if you want to keep a competitive advantage, continue innovating, and push boundaries to differentiate yourself. The forces at work in the market, the increased complexities, the time, investment and expertise required to remain competitive all will likely leave those behind who are not making the effort in order to exploit alternative data.
The supply side is exploding, far beyond the size we could have expected only three years ago. We expect this to continue, and will make it even harder for funds to keep tabs on the entire universe of data sets on offer.
CFM: From our experience, and from what you have said, I think our conviction is accurate in that alternative data has gone from a nice-to-have, to a have-to-have. And therefore one can only expect the finance industry to become even more quantitative. And part of the fuel mix is going to be alternative data.
RL: I completely agree with that assessment, not just because it is our business, but because the trends are clear.
For more details about Neudata and to get in touch, please visit their website: LINK
Interested readers can access the Neudata H1 2021 Alternative Data Trends Report here: LINK
CFM, in 2019, launched an initiative with Columbia University’s Program for Economic Research (PER), one of the world’s leading economics research programs, to explore the use of alternative data sources. For more information, and to register for upcoming events, visit the website: LINK
CFM was proud to have contributed to one of the major studies investigating the trends and uses of alternative data for alternative investment strategies. To download the report, ‘Casting the Net. How Hedge Funds are Using Alternative Data’, please visit the AIMA website: LINK
.
[1] Details for access to this report is available at the bottom of this interview
DISCLAIMER
THE TEXT IS AN EDITED TRANSCRIPT OF A PHONE INTERVIEW WITH RADO LIPUŠ IN JULY 2021. THE VIEWS AND OPINIONS EXPRESSED IN THIS INTERVIEW ARE THOSE OFRADO LIPUŠ AND MAY NOT NECESSARILY REFLECT THE OFFICIAL POLICY OR POSITION OF EITHER CFM OR ANY OF ITS AFFILIATES. THE INFORMATION PROVIDED HEREIN IS GENERAL INFORMATION ONLY AND DOES NOT CONSTITUTE INVESTMENT OR OTHER ADVICE. ANY STATEMENTS REGARDING MARKET EVENTS, FUTURE EVENTS OR OTHER SIMILAR STATEMENTS CONSTITUTE ONLY SUBJECTIVE VIEWS, ARE BASED UPON EXPECTATIONS OR BELIEFS, INVOLVE INHERENT RISKS AND UNCERTAINTIES AND SHOULD THEREFORE NOT BE RELIED ON. FUTURE EVIDENCE AND ACTUAL RESULTS COULD DIFFER MATERIALLY FROM THOSE SET FORTH, CONTEMPLATED BY OR UNDERLYING THESE STATEMENTS. IN LIGHT OF THESE RISKS AND UNCERTAINTIES, THERE CAN BE NO ASSURANCE THAT THESE STATEMENTS ARE OR WILL PROVE TO BE ACCURATE OR COMPLETE IN ANY WAY.